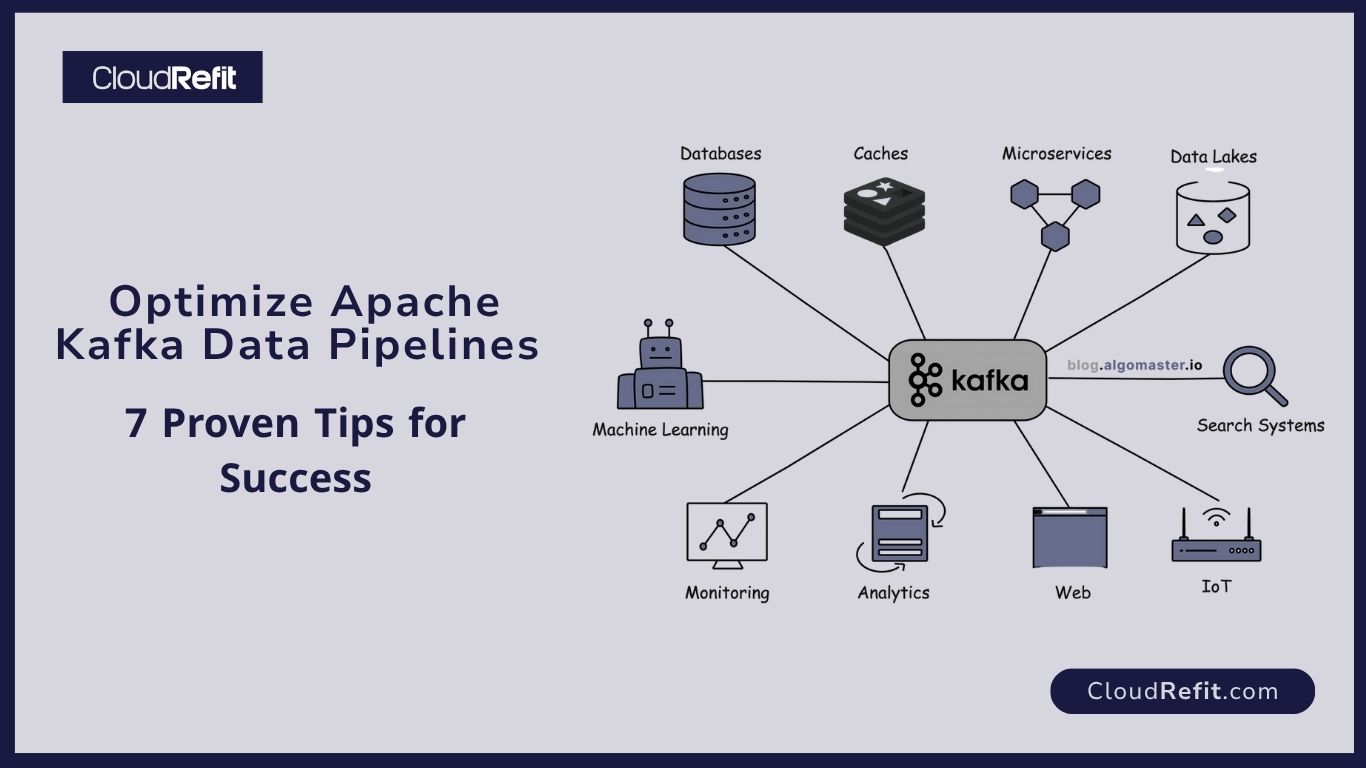
In today’s data‑driven world, organizations rely on Apache Kafka to ingest, process, and analyze high‑velocity event streams. As the de facto platform for building distributed, fault‑tolerant data streaming architectures, Kafka enables you to:
- Deliver analytics with millisecond latency
- Ensure event durability and exactly‑once processing
- Scale horizontally to handle millions of events per second
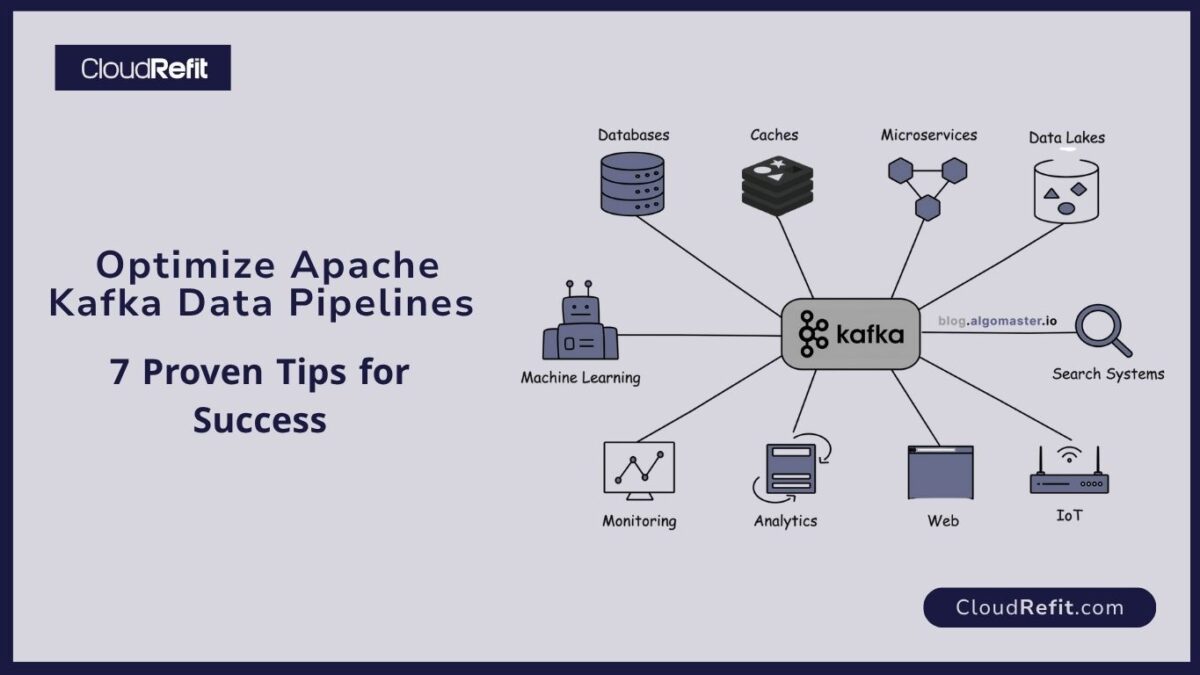
This guide covers end‑to‑end strategies for optimizing real‑time data pipelines with Apache Kafka, helping startups and enterprises alike achieve robust, cost‑effective streaming solutions.
Core Components of a Kafka‑Based Pipeline
A typical real‑time data pipeline using Apache Kafka includes :
1. Producers
Applications or connectors that publish events to Kafka topics.
Use asynchronous batching to maximize throughput.
2. Brokers
Kafka nodes that store and replicate data across partitions.
Configure replication factor ≥ 3 for fault tolerance.
3. Consumers & Consumer Groups
Stream processors or microservices subscribing to topics.
Leverage consumer groups to parallelize processing and maintain offset tracking.
4. ZooKeeper / Kafka Controller
Manages broker metadata and leader election (or use Kafka’s new KRaft mode).
5. Connectors & Stream Processors
Kafka Connect for integrating with databases, object stores, and messaging systems.
Kafka Streams or ksqlDB for in‑line transformations and aggregations.
Optimizing each component ensures your Apache Kafka pipelines remain high‑performing under load.
Cluster Architecture & Deployment
3.1 Hardware & Sizing
- Memory & Disk: Allocate ample RAM for page caching and SSDs for low‑latency I/O.
- Network: Use 10 Gbps NICs to prevent bottlenecks in Apache Kafka communication.
3.2 Partitioning Strategy
- Determine number of partitions based on expected throughput and consumer parallelism.
- More partitions boost concurrency but increase overhead—strike the right balance.
3.3 Replication & Durability
- Set min.insync.replicas ≥ 2 to protect against broker failures.
- Use acks=all in producer configs to ensure commits to all replicas.
Performance Tuning
4.1 Producer Configurations
- batch.size: Increase batch size for higher throughput in Apache Kafka streams.
- linger.ms: Introduce a small delay (e.g., 5 ms) to accumulate more messages per batch.
- compression.type: Enable Snappy or LZ4 to reduce network bandwidth.
4.2 Consumer Optimizations
- fetch.min.bytes & fetch.max.wait.ms: Tune to balance latency and bandwidth.
- max.poll.records: Adjust to control processing granularity and avoid long GC pauses.
4.3 Broker Settings
- num.network.threads & num.io.threads: Scale with CPU core counts and load.
- log.retention.hours & log.segment.bytes: Configure retention to meet SLAs without over‑consuming disk.
Monitoring & Alerting
Effective monitoring is critical for Apache Kafka pipelines:
- Broker Metrics: Throughput (BytesInPerSec), request rates, under‑replicated partitions.
- Consumer Lag: Use tools like Burrow or Cruise Control to detect backlogs.
- End‑to‑End Latency: Track from producer timestamp to consumer processing time.
- System Health: Monitor JVM GC pauses, disk usage, and network I/O.
Integrate these metrics into Grafana dashboards and configure Slack/PagerDuty alerts for anomaly detection.
Security & Compliance
Protect your Apache Kafka deployment with:
- Encryption in Transit (TLS): Secure all broker‑to‑broker and client‑to‑broker communications.
- Authentication (SASL): Implement Kerberos or OAuth for client identity.
- Authorization (ACLs): Restrict topic access to specific producers and consumers.
- Audit Logging: Retain access logs for compliance (e.g., GDPR, PCI DSS).
Advanced Stream Processing
Enhance your pipelines with Apache Kafka tools:
- Kafka Streams: Build microservices for windowed aggregations, joins, and stateful transformations inline.
- ksqlDB: Write SQL queries against your real‑time streams for rapid prototyping and dashboards.
- Kafka Connect: Leverage connectors for JDBC, Elasticsearch, and cloud storage to simplify integration.
Real‑World Use Cases
1. Financial Fraud Detection
Ingest payment events, enrich with risk scores, and trigger alerts within milliseconds using Apache Kafka.
2. Industrial IoT Monitoring
Stream sensor data from factory equipment to predictive maintenance models in real time.
3. E‑commerce Recommendation Engines
Update product recommendations instantly based on user clickstreams and purchase events.
These scenarios demonstrate the power of Apache Kafka for instant insights and automated decision‑making.
Best Practices & Common Pitfalls
- Start Simple: Begin with a small cluster and a few topics; scale as usage grows.
- Test Under Load: Use kafka-producer-perf-test to simulate peak traffic.
- Avoid Oversharding: Too many partitions can overwhelm the controller.
- Regular Upgrades: Keep Kafka updated for performance improvements and security patches.
Conclusion
By following this comprehensive guide, you can architect and optimize Apache Kafka pipelines that deliver reliable, low‑latency streaming at scale.
Ready to enhance your streaming architecture?
📩 Book a free consultation with CloudRefit to design and deploy high‑performance Apache Kafka pipelines that drive your business forward.
🔗 www.cloudrefit.com | ✉️ [email protected]